5 EML Schema
EML is defined by a set of XML Schema files that define the types and structure of a valid EML document. In this chapter, all of the elements and types defined within those EML schemas are displayed using diagrams illustrating the relationships among these components.
Browse EML Schema Documentation
5.1 The EML Module and Resources
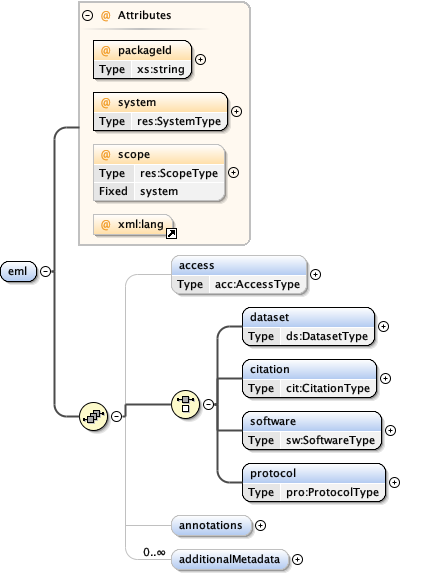
5.1.1 The eml module - A metadata container
Links:
{kind=link}
The eml module is a wrapper container that allows the inclusion of any metadata content in a single EML document. The eml module is used as a container to hold structured descriptions of ecological resources. In EML, the definition of a resource comes from the The Dublin Core Metadata Initiative, which describes a general element set used to describe "networked digital resources". The top-level structure of EML has been designed to be compatible with the Dublin Core syntax. In general, dataset resources, literature resources, software resources, and protocol resources comprise the list of information that may be described in EML. EML is largely designed to describe digital resources, however, it may also be used to describe non-digital resources such as paper maps and other non-digital media. In EML, the definition of a "Data Package" is the combination of both the data and metadata for a resource. So, data packages are built by using the <eml> wrapper, which will include all of the metadata, and optionally the data (or references to them). All EML packages must begin with the <eml> tag and end with the </eml> tag.
The eml module may be extended to describe other resources by means of its optional sub-field, <additionalMetadata>. This field is largely reserved for the inclusion of metadata that may be highly discipline specific and not covered in this version of EML, or it may be used to internally extend fields within the EML standard.
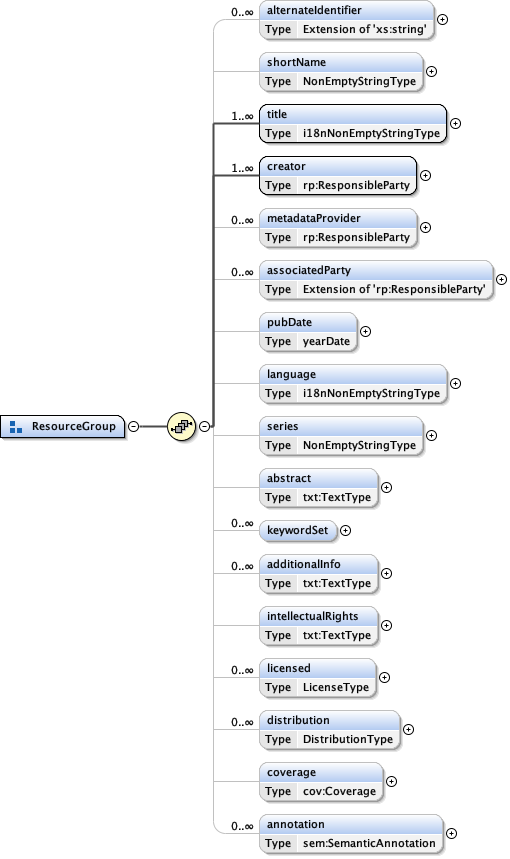
5.1.2 The eml-resource module - Base information for all resources
Links:
{kind=link}
The eml-resource module contains general information that describes dataset resources, literature resources, protocol resources, and software resources. Each of the above four types of resources share a common set of information, but also have information that is unique to that particular resource type. Each resource type uses the eml-resource module to document the information common to all resources, but then extend eml-resource with modules that are specific to that particular resource type. For instance, all resources have creators, titles, and perhaps keywords, but only the dataset resource would have a "data table" within it. Likewise, a literature resource may have an "ISBN" number associated with it, whereas the other resource types would not.
The eml-resource module is exclusively used by other modules, and is therefore not a stand-alone module. The following four modules are used to describe separate resources: datasets, literature, software, and protocols. However, note that the dataset module makes use of the other top-level modules by importing them at different levels. For instance, a dataset may have been produced using a particular protocol, and that protocol may come from a protocol document in a library of protocols. Likewise, citations are used throughout the top-level resource modules by importing the literature module.
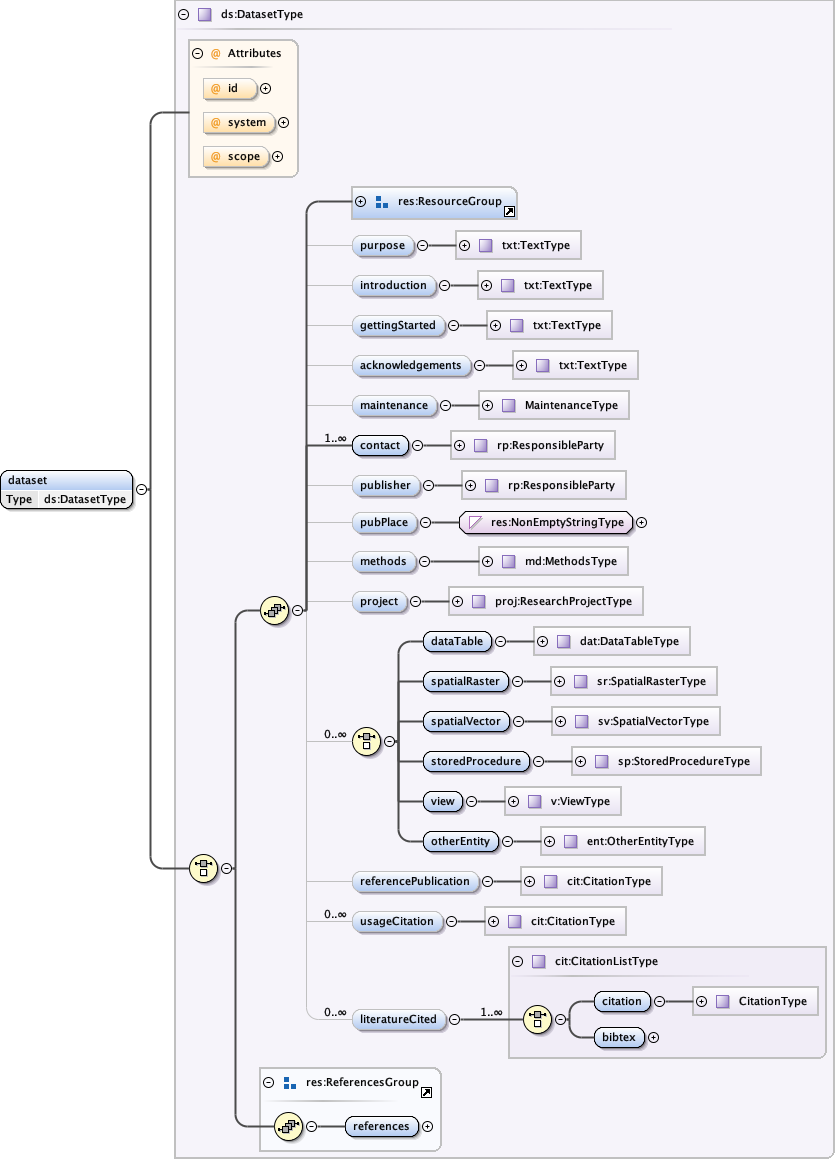
5.1.3 The eml-dataset module - Dataset specific information
Links:
{kind=link}
The eml-dataset module contains general information that describes dataset resources. It is intended to provide overview information about the dataset: broad information such as the title, abstract, keywords, contacts, maintenance history, purpose, and distribution of the data themselves. The eml-dataset module also imports many other modules that are used to describe the dataset in fine detail. Specifically, it uses the eml-methods module to describe methodology used in collecting or processing the dataset, the eml-project module to describe the overarching research context and experimental design, the eml-access module to define access control rules for the data and metadata, and the eml-entity module to provide detailed information about the logical structure of the dataset. A dataset can be (and often is) composed of a series of data entities (tables) that are linked together by particular integrity constraints.
The eml-dataset module, like other modules, may be "referenced" via the <references> tag. This allows a dataset to be described once, and then used as a reference in other locations within the EML document via its ID.
5.1.4 The eml-literature module - Citation-specific information
Links:
{kind=link}
The eml-literature module contains information that describes literature resources. It is intended to provide overview information about the literature citation, including title, abstract, keywords, and contacts. Citation types follow the conventions laid out by EndNote, and there is an attempt to represent a compatible subset of the EndNote citation types. These citation types include: article, book, chapter, edited book, manuscript, report, thesis, conference proceedings, personal communication, map, generic, audio visual, and presentation. The generic citation type would be used when one of the other types will not work.
There are three unique CitationType elements that may be employed within a eml-dataset module, including the <literatureCited>, <usageCitation>, and <referencePublication> elements. The purpose and examples of each CitationType element type are detailed below.
Similar to other eml modules, each of the CitationType elements may be referenced via the <references> tag. The <references> tag allows a citation to be described once then used as a reference in other locations within the EML document via its reference ID.
As of EML 2.2.0, each CitationType element can use the <bibtex> element as an alternative to encoding citations in the EML XML structures. BibTeX entries generally play well inside of XML structures, but XML escaping is still needed for special characters so consider embedding BibTeX entries in CDATA blocks if XML escaping is cumbersome.
5.1.4.1 eml-literature module - literature cited
Citations to articles or other resources that are referenced in the data set or its associated metadata should be included in a <literatureCited> element. <literatureCited> is a CitationListType cataloging one or more citations that represent a bibliography of works related to the data set for reference, comparison, or other purposes. These citations can be a series of <citation> elements, a <bibtex> element featuring one or more BibTeX-style citations, or a mix of the two types.
Example of the <literatureCited> element:
<dataset>
...
<literatureCited>
<citation>
<bibtex>
@article{fegraus_2005,
title = {Maximizing the {Value} of {Ecological} {Data} with {Structured} {Metadata}: {An} {Introduction} to {Ecological} {Metadata} {Language} ({EML}) and {Principles} for {Metadata} {Creation}},
journal = {Bulletin of the Ecological Society of America},
author = {Fegraus, Eric H. and Andelman, Sandy and Jones, Matthew B. and Schildhauer, Mark},
year = {2005},
pages = {158--168}
}
</bibtex>
</citation>
<citation>
<title>Title of a paper that this dataset, or its metadata, references.</title>
<creator>
<individualName>
<givenName>Mark</givenName>
<surName>Jarkady</surName>
</individualName>
</creator>
<pubDate>2017</pubDate>
<article>
<journal>EcoSphere</journal>
<publicationPlace>https://doi.org/10.1002/ecs2.2166</publicationPlace>
</article>
</citation>
<bibtex>
@article{hampton\_2017,
title = {Skills and {Knowledge} for {Data}-{Intensive} {Environmental} {Research}},
volume = {67},
copyright = {All rights reserved},
issn = {0006-3568, 1525-3244},
url = {https://academic.oup.com/bioscience/article-lookup/doi/10.1093/biosci/bix025},
doi = {10.1093/biosci/bix025},
language = {en},
number = {6},
urldate = {2018-02-15},
journal = {BioScience},
author = {Hampton, Stephanie E. and Jones, Matthew B. and Wasser, Leah A. and Schildhauer, Mark P. and Supp, Sarah R. and Brun, Julien and Hernandez, Rebecca R. and Boettiger, Carl and Collins, Scott L. and Gross, Louis J. and Fernández, Denny S. and Budden, Amber and White, Ethan P. and Teal, Tracy K. and Labou, Stephanie G. and Aukema, Juliann E.},
month = jun,
year = {2017},
pages = {546--557}
}
@article{collins\_2018,
title = {Temporal heterogeneity increases with spatial heterogeneity in ecological communities},
volume = {99},
copyright = {All rights reserved},
issn = {00129658},
url = {http://doi.wiley.com/10.1002/ecy.2154},
doi = {10.1002/ecy.2154},
language = {en},
number = {4},
urldate = {2018-04-16},
journal = {Ecology},
author = {Collins, Scott L. and Avolio, Meghan L. and Gries, Corinna and Hallett, Lauren M. and Koerner, Sally E. and La Pierre, Kimberly J. and Rypel, Andrew L. and Sokol, Eric R. and Fey, Samuel B. and Flynn, Dan F. B. and Jones, Sydney K. and Ladwig, Laura M. and Ripplinger, Julie and Jones, Matt B.},
month = apr,
year = {2018},
pages = {858--865}
}
</bibtex>
</literatureCited>
...
</dataset>5.1.4.2 eml-literature module - usage citation
A citation to an article or other resource in which the data set is used or referenced should be included in a <usageCitation> element, a CitationType detailing a literature resource that has used or references this data set. It is not expected that one or more usage citations will necessarily be an exhaustive list of resources that employ the data set, but rather will serve as a example(s) and pointer(s) to scholarly works in which this data set has been used. The <usageCitation> element can be a <citation> or <bibtex> element.
Example of the
<dataset>
...
<usageCitation>
<citation>
<title>Title of a paper that uses this dataset or its metadata</title>
<creator>
<individualName>
<givenName>Mark</givenName>
<surName>Jarkady</surName>
</individualName>
</creator>
<pubDate>2017</pubDate>
<article>
<journal>EcoSphere</journal>
<publicationPlace>https://doi.org/10.1002/ecs2.2166</publicationPlace>
</article>
</citation>
</usageCitation>
<usageCitation>
<bibtex>
<![CDATA[
@article{doi:10.1890/10-0423.1,
author = {Lerman, Susannah B. and Warren, Paige S.},
title = {The conservation value of residential yards: linking birds and people},
journal = {Ecological Applications},
volume = {21},
number = {4},
pages = {1327-1339},
keywords = {Arizona, USA, CAP LTER, human–wildlife interactions, long-term ecological research, native landscaping, residential yards, socio-ecology, urban birds},
doi = {10.1890/10-0423.1},
url = {https://esajournals.onlinelibrary.wiley.com/doi/abs/10.1890/10-0423.1},
eprint = {https://esajournals.onlinelibrary.wiley.com/doi/pdf/10.1890/10-0423.1}
}
]]>
</bibtex>
</usageCitation>
...
</dataset>5.1.4.3 eml-literature module - reference publication
A citation to an article or other resource that serves as an important reference for a data set should be documented in a <referencePublication> element. Anyone using the data set should generally cite the data set itself (using the creator, pubDate, title, publisher, and packageId fields), and consider providing an additional citation to the reference publication. The <referencePublication> element will typically be used when the data set and a companion or associated paper are published near concurrently. Common cases where a reference publication may be useful include when a data paper is published that describes the dataset, or when a paper is intended to be the canonical or exemplar reference to the dataset – these are features that distinguish the <referencePublication> CitationType from the <usageCitation> CitationType.
Example of the <referencePublication> element:
<dataset>
...
<referencePublication>
<bibtex>
@article{doi:10.1890/14-2252.1,
author = {Edwards, Kyle F. and Klausmeier, Christopher A. and Litchman, Elena},
title = {Nutrient utilization traits of phytoplankton},
journal = {Ecology},
volume = {96},
number = {8},
pages = {2311-2311},
keywords = {algae, allometry, competition, Droop, Monod, nitrogen, phosphorus, physiology, stoichiometry, uptake kinetics},
doi = {10.1890/14-2252.1},
url = {https://esajournals.onlinelibrary.wiley.com/doi/abs/10.1890/14-2252.1},
eprint = {https://esajournals.onlinelibrary.wiley.com/doi/pdf/10.1890/14-2252.1}
}
</bibtex>
</referencePublication>
...
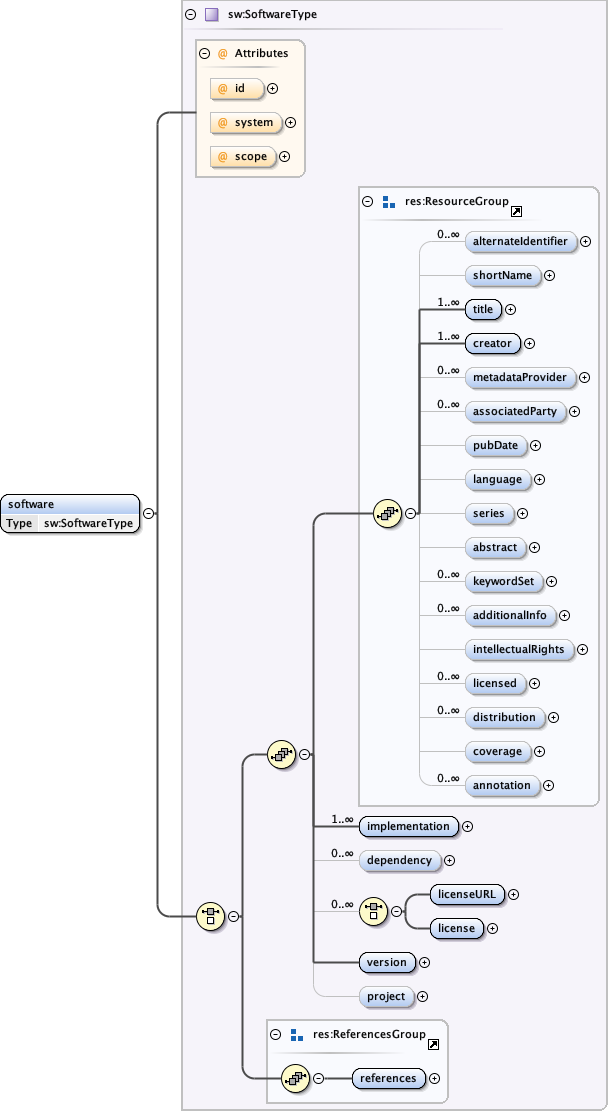
</dataset>5.1.5 The eml-software module - Software specific information
Links:
{kind=link}
The eml-software module contains general information that describes software resources. This module is intended to fully document software that is needed in order to view a resource (such as a dataset) or to process a dataset. The software module is also imported into the eml-methods module in order to document what software was used to process or perform quality control procedures on a dataset.
The eml-software module, like other modules, may be "referenced" via the <references> tag. This allows a software resource to be described once, and then used as a reference in other locations within the EML document via its ID.
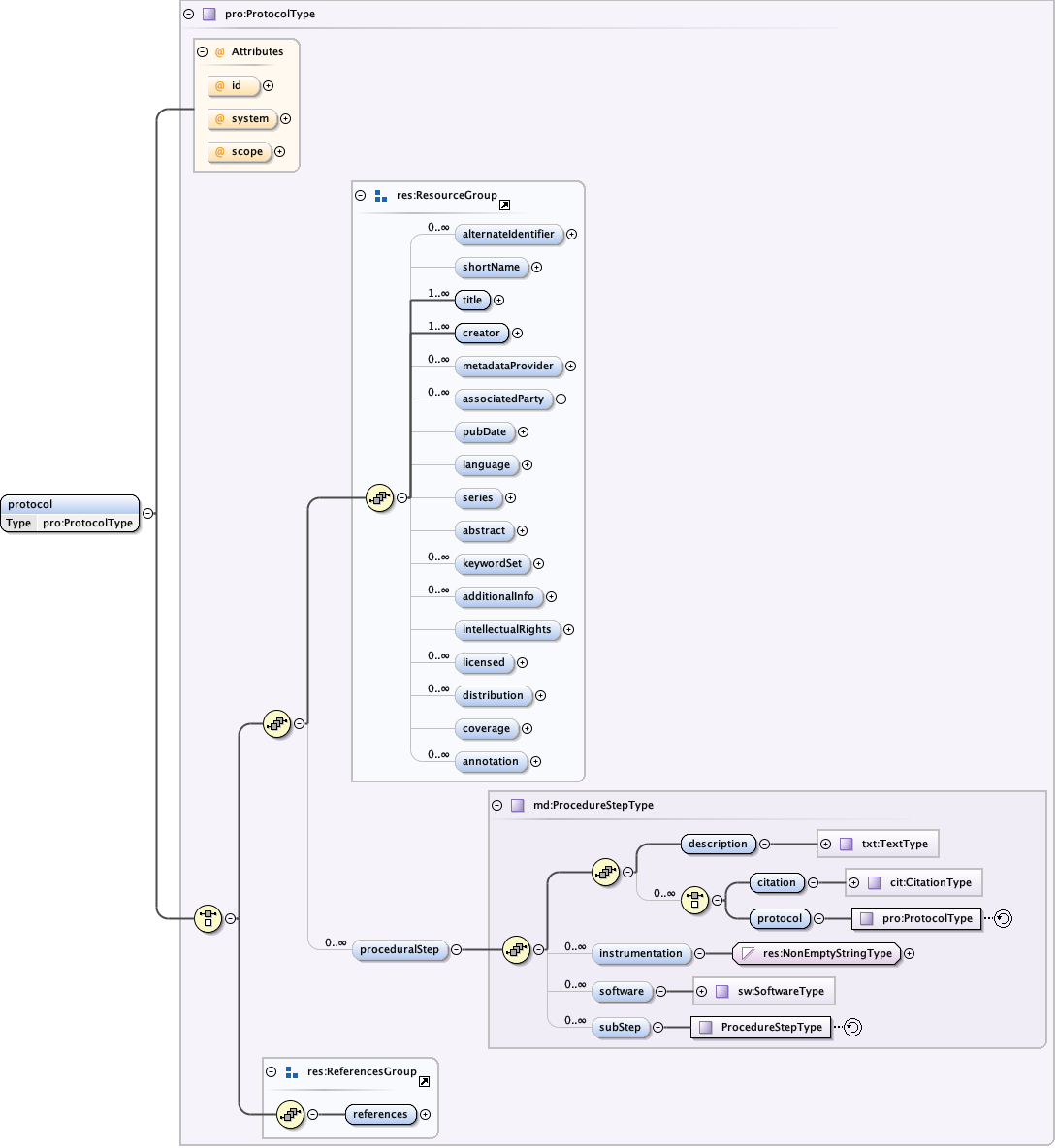
5.1.6 The eml-protocol module - Research protocol specific information
Links:
{kind=link}
The EML Protocol Module is used to define abstract, prescriptive procedures for generating or processing data. Conceptually, a protocol is a standardized method.
Eml-protocol resembles eml-methods; however, eml-methods is descriptive (often written in the declarative mood: "I took five subsamples...") whereas eml-protocol is prescriptive (often written in the imperative mood: "Take five subsamples..."). A protocol may have versions, whereas methods (as used in eml-methods) should not.
5.2 Data Structure Modules
The following three modules are used to document the logical layout of a dataset. Many datasets are comprised of multiple entities (e.g. a series of tabular data files, or a set of GIS features, or a number of tables in a relational database). Each entity within a dataset may contain one or more attributes (e.g. multiple columns in a data file, multiple attributes of a GIS feature, or multiple columns of a database table). Lastly, there may be both simple or complex relationships among the entities within a dataset. The relationships, or the constraints that are to be enforced in the dataset, are described using the eml-constraint module. All entities share a common set of information (described using eml-entity), but some discipline specific entities have characteristics that are unique to that entity type. Therefore, the eml-entity module is extended for each of these types (dataTable, spatialRaster, spatialVector, etc...) which are described in the next section.
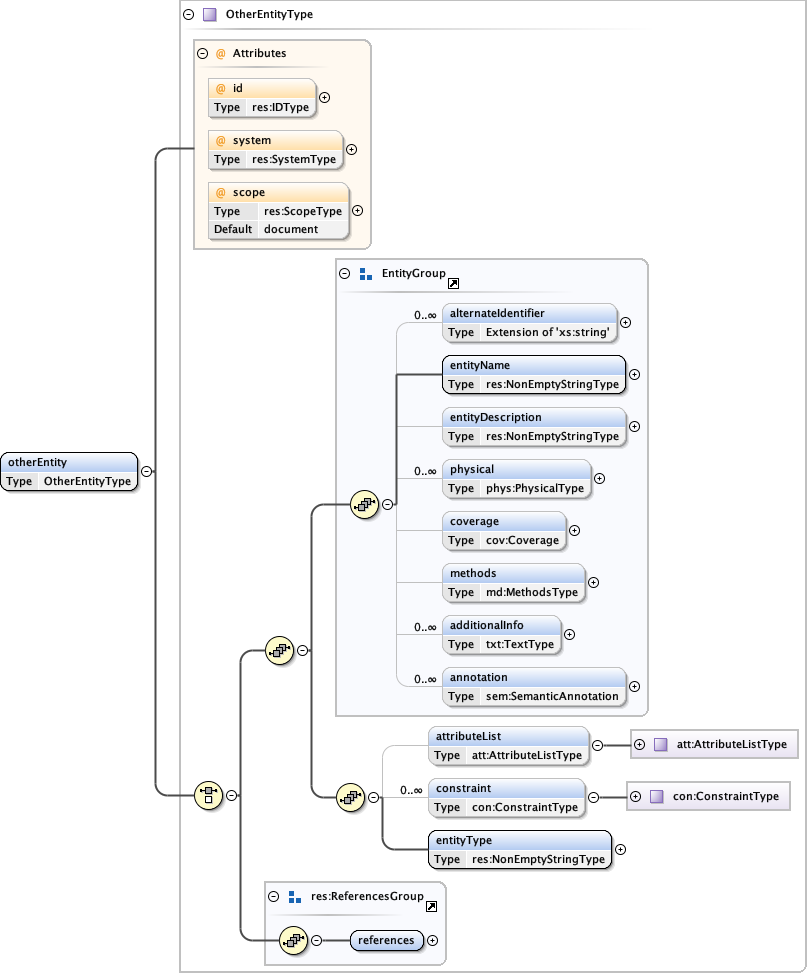
5.2.1 The eml-entity module - Entity level information within datasets
Links:
{kind=link}
The eml-entity module defines the logical characteristics of each entity in the dataset. Entities are usually tables of data (eml-dataTable). Data tables may be ascii text files, relational database tables, spreadsheets or other type of tabular data with a fixed logical structure. Related to data tables are views (eml-view) and stored procedures (eml-storedProcedure). Views and stored procedures are produced by an RDBMS or related system. Other types of data such as: raster (eml-spatialRaster), vector (eml-spatialVector) or spatialReference image data are also data entities. An otherEntity element would be used to describe types of entities that are not described by any other entity type. Each of these entity type uses the eml-entity module elements as it’s base set of elements, but then extends the base with entity-specific elements. Note that the eml-spatialReference module is not an entity type, but is rather a common set of elements used to describe spatial reference systems in both eml-spatialRaster and eml-spatialVector. It is described here in relation to those two modules.
The eml-entity module, like other modules, may be “referenced” via the
<references> tag. This allows an entity document to be described once,
and then used as a reference in other locations within the EML document
via its ID.
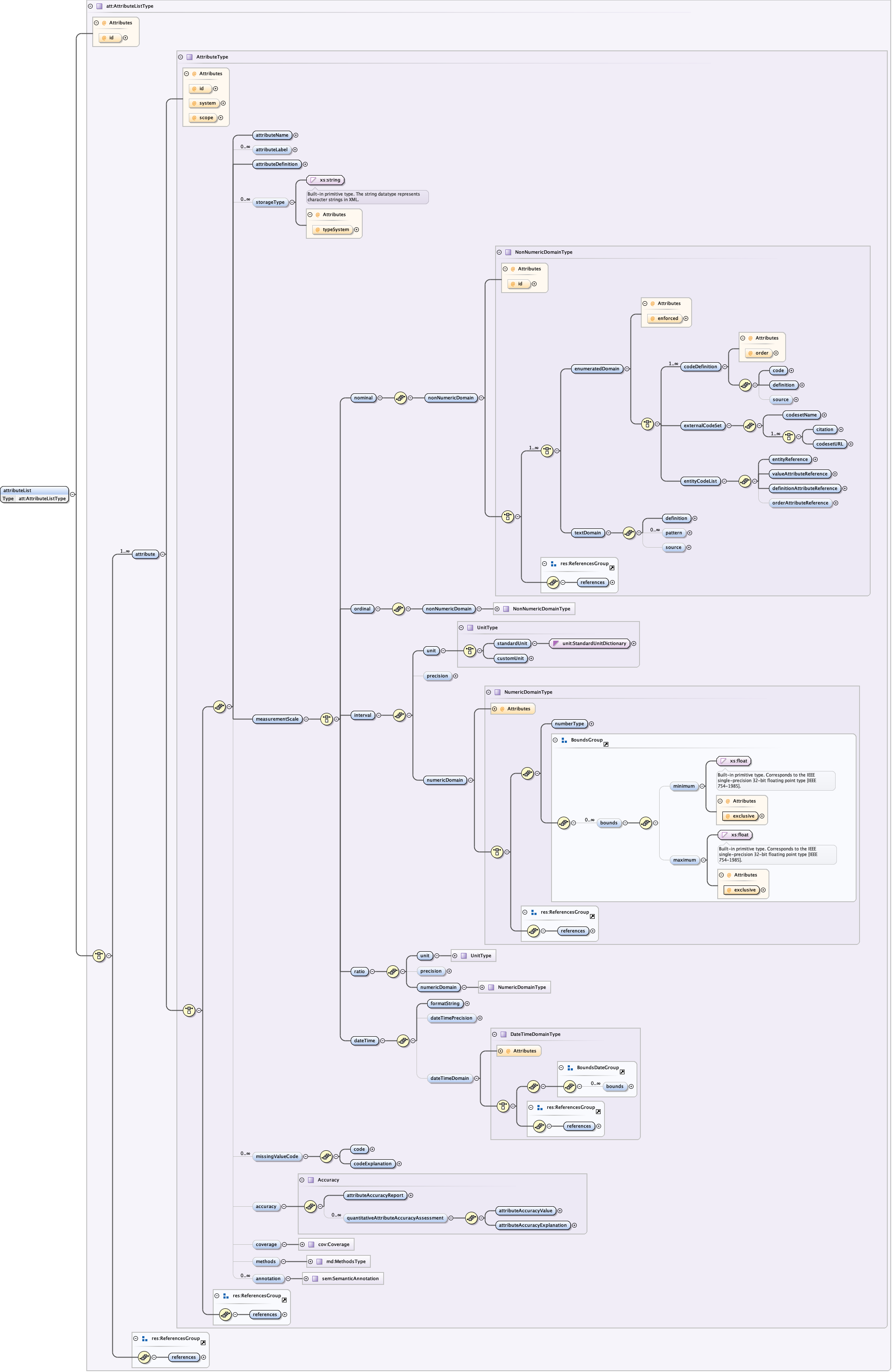
5.2.2 The eml-attribute module - Attribute level information within dataset entities
Links:
{kind=link}
The eml-attribute module describes all attributes (variables) in a data
entity: dataTable, spatialRaster, spatialVector, storedProcedure, view
or otherEntity. The description includes the name and definition of each
attribute, its domain, definitions of coded values, definitions of missing
values, and other pertinent
information. Two structures exist in this module: 1. attribute is used
to define a single attribute; 2. attributeList is used to define a list
of attributes that go together in some logical way.
The eml-attribute module, like other modules, may be "referenced" via the <references> tag. This allows an attribute document to be described once, and then used as a reference in other locations within the EML document via its ID.
5.2.2.1 Philosophy of Attribute Units
The concept of "unit" represents one of the most fundamental categories of metadata. The classic example of data entropy is the case in which a reported numeric value loses meaning due to lack of associated units. Much of ecology is driven by measurement, and most measurements are inherently comparative. Good data description requires a representation of the basis for comparison, i.e., the unit. In modeling the attribute element, the authors of EML drew inspiration from the NIST Reference on Constants, Units, and Uncertainty. This document defines a unit as "a particular physical quantity, defined and adopted by convention, with which other particular quantities of the same kind are compared to express their value." The authors of the EML 2.0 specification (hereafter "the authors") decided to make the unit element required, wherever possible.
Units may also be one of the most problematic categories of metadata. For instance, there are many candidate attributes that clearly have no units, such as named places and letter grades. There are other candidate attributes for which units are difficult to identify, despite some suspicion that they should exist (e.g. pH, dates, times). In still other cases, units may be meaningful, but apparently absent due to dimensional analysis (e.g. grams of carbon per gram of soil). The relationship between units and dimensions likewise is not completely clear.
The authors decided to sharpen the model of attribute by nesting unit under measurementScale. Measurement Scale is a data typology, borrowed from Statistics, that was introduced in the 1940's. Under the adopted model, attributes are classified as nominal, ordinal, interval, and ratio. Though widely criticized, this classification is well-known and provides at least first-order utility in EML. For example, nesting unit under measurementScale allows EML to prevent its meaningless inclusion for categorical data -- an approach judged superior to making unit universally required or universally optional.
The sharpening of the attribute model allowed the elimination of the unit type "undefined" from the standard unit dictionary (see eml-unitDictionary.xml). It seemed self-defeating to require the unit element exactly where appropriate, yet still allow its content to be undefined. An attribute that requires a unit definition is malformed until one is provided. The unit type "dimensionless" is preserved, however. In EML 2.0, it is synonymous with "unitless" and represents the case in which units cannot be associated with an attribute for some reason, despite the proper classification of that attribute as interval or ratio. Dimensionless may itself be an anomaly arising from the limitations of the adopted measurement scale typology.
Closely related to the concept of unit is the concept of attribute domain. The authors decided that a well-formed description of an attribute must include some indication of the set of possible values for that attribute. The set of possible values is useful, perhaps necessary, for interpreting any particular observed value. While universally required, attribute domain has different forms, depending on the associated measurement scale.
The element storageType has an obvious relationship to domain. It gives some indication of the range of possible values of an attribute, and also gives some (potentially critical) operability information about the way the attribute is represented or construed in the local storage system. The storageType element seems to fall in a gray area between the logical and physical aspects of stored data. Neither comfortable with eliminating it nor with making it required, the authors left it available but optional under attribute. In addition, it is repeatable so that different storage types can be provided for various systems (e.g., different databases might use different types for columns, even though the domain of the attribute is the same regardless of which database is used).
Attributes representing dates, times, or combinations thereof (hereafter "dateTime") were the most difficult to model in EML. Is dateTime of type interval or ordinal? Does it have units or not? Strong cases can be made on each side of the issue. The confusion may reflect the limitations of the measurement scale typology. The final resolution of the dateTime model is probably somewhat arbitrary. There was clearly a need, however, to allow for the interoperability of dateTime formats. EML 2.0 tries to provide an unambiguous mechanism for describing the format of dateTime values by providing a separate category for date and time values. This "dateTime" measurement scale allows users to explicitly label attributes that contain Gregorian date and time values, and allows them to provide the information needed to parse these values into their appropriate components (e.g., days, months, years).
Representations of both coded values (for nominal and ordinal attributes)
and missing value codes are critical metadata. Coded values need to be
defined in metadata for proper interpretation. EML provides the enumeratedDomain
field for explicitly listing codes and their definitions, or through elements
to reference external codesets and codes that are defined in other tables in
a dataset. Missing values can also be coded and defined in the
missingValueCode element. Providing an explicit indication of
“missingness” as a coded value that has an explicit
interpretation eliminates the guesswork that happens when missing values are
expressed simply as empty cells with NULL values and no explanation. While it
might seem simple to provide an emty cell in a csv file, the interpreation of
that value is left ambiguous. Researchers would be better served to define explicit
missing value codes, e.g., one for ‘Data not collected’ and another for
‘Data corrupted during network transfer’.
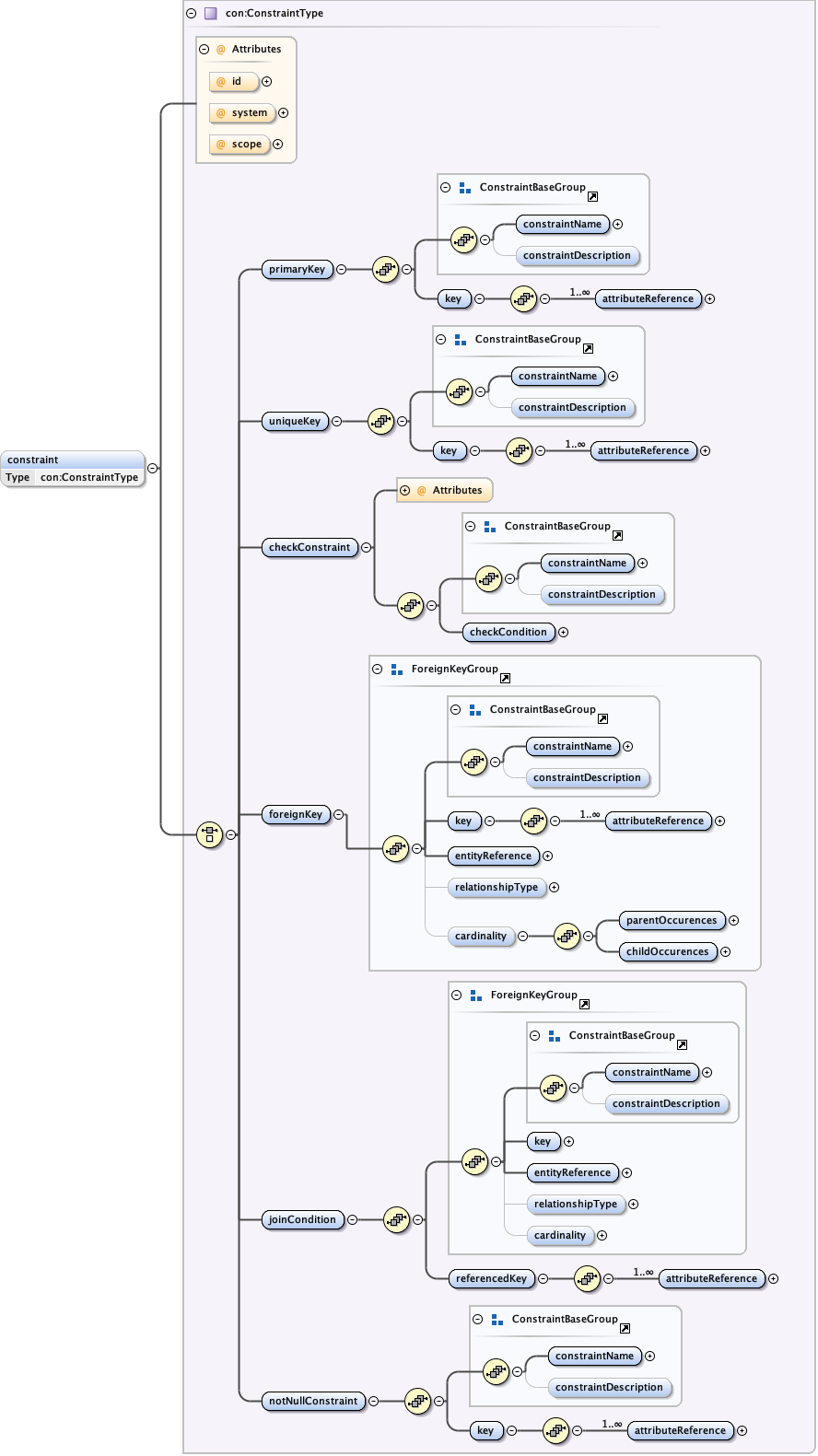
5.2.3 The eml-constraint module - Relationships among and within dataset entities
Links:
{kind=link}
The eml-constraint schema defines the integrity constraints between entities (e.g., data tables) as they would be maintained in a relational management system. These constraints include primary key constraints, foreign key constraints, unique key constraints, check constraints, and not null constraints, among potential others.
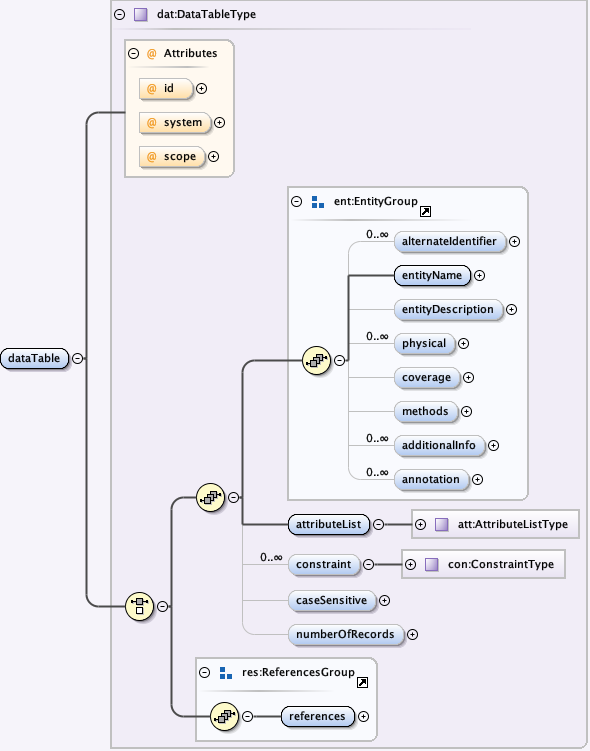
5.2.4 The eml-dataTable module - Logical information about data table entities
Links:
{kind=link}
The eml-dataTable module is used to describe the logical characteristics of each tabular set of information in a dataset. A series of comma-separated text files may be considered a dataset, and each file would subsequently be considered a dataTable entity within the dataset. Since the eml-dataTable module extends the eml-entity module, it uses all of the common entity elements to describe the table, along with a few elements specific to just data table entities. The eml-dataTable module allows for the description of each attribute (column/field/variable) within the data table through the use of the eml-attribute module. Likewise, there are fields used to describe the physical distribution of the data table, its overall coverage, the methodology used in creating the data, and other logical structure information such as its orientation, case sensitivity, etc.
5.2.5 The eml-spatialRaster module - Logical information about regularly gridded geospatial image data
Links:
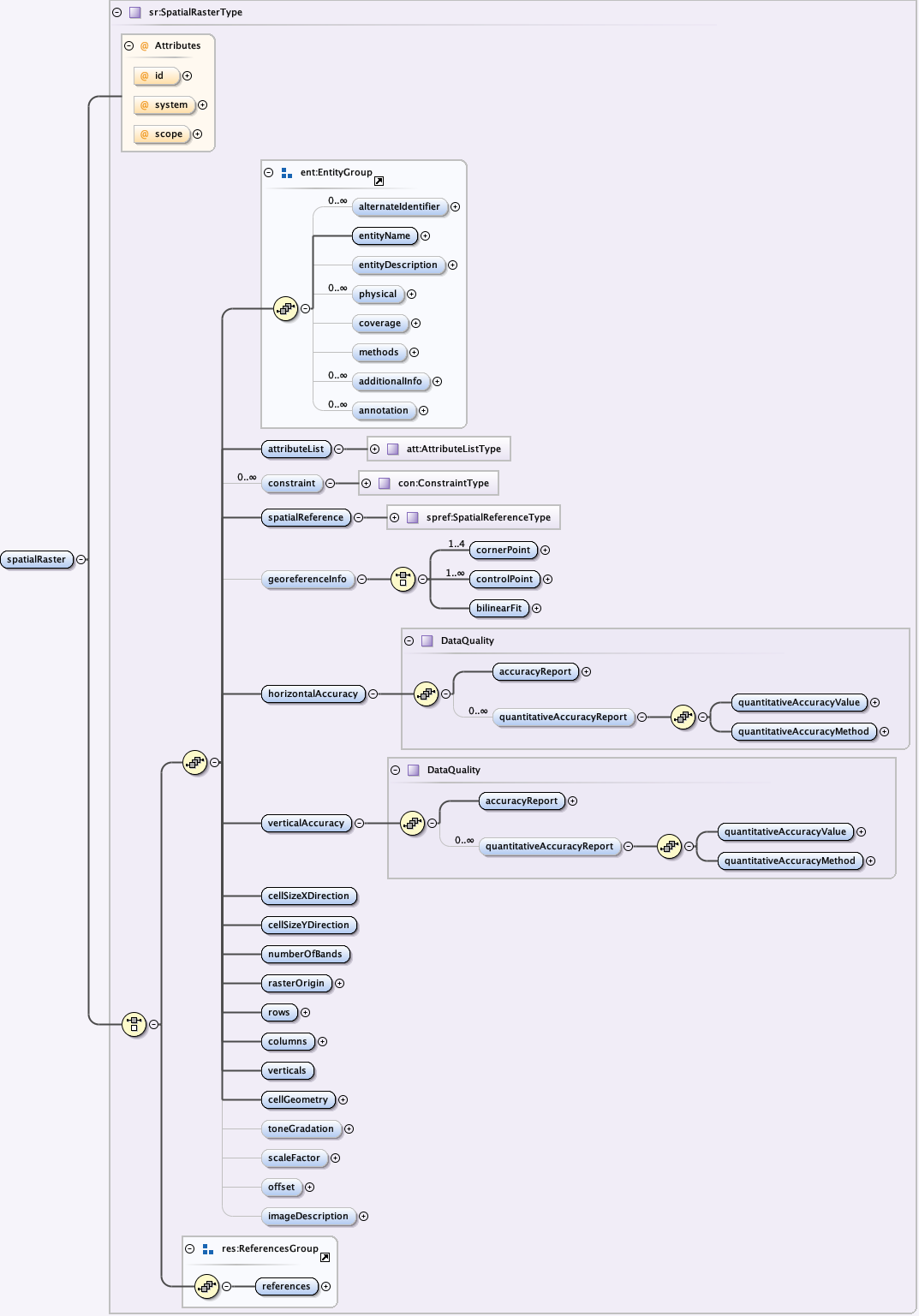{kind=link}
The eml-spatialRaster module allows for the description of entities composed of rectangular grids of data values that are usually georeferenced to a portion of the earth's surface. Specific attributes of a spatial raster can be documented here including the spatial organization of the raster cells, the cell data values, and if derived via imaging sensors, characteristics about the image and its individual bands.
5.2.6 The eml-spatialVector module - Logical information about non-gridded geospatial image data
Links:
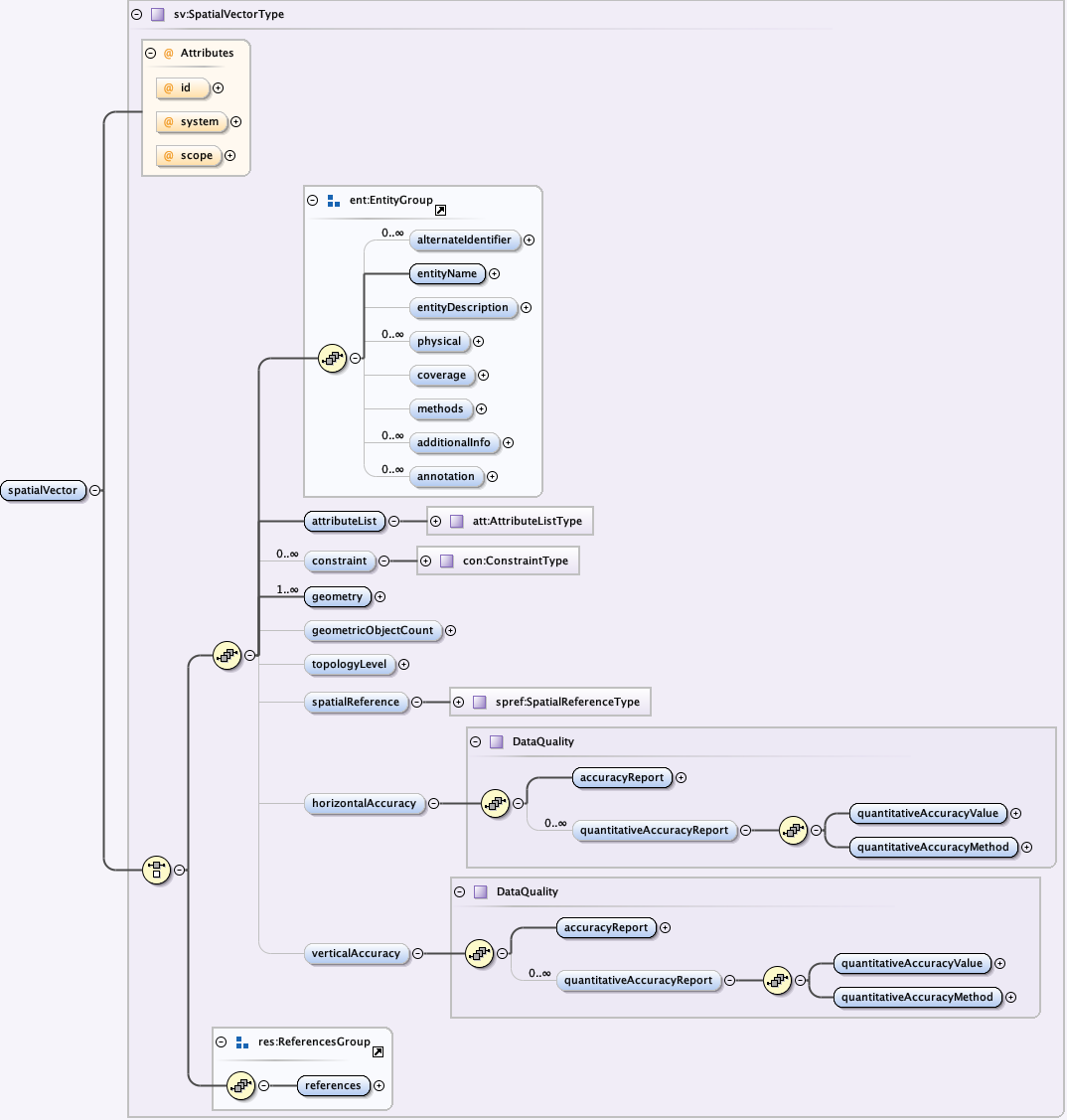{kind=link}
The eml-spatialVector module allows for the description of spatial objects in a GIS system that are not defined in a regularly gridded pattern. These geometries include points and vectors and the relationships among them. Specific attributes of a spatial vector can be documented here including the vector's geometry type, count and topology level.
5.2.7 Schema for validating spatial referencing descriptions
This module defines both projected and unprojected coordinate systems for referencing the spatial coordinates of a dataset to the earth. The schema is based on that used by Environmental Systems Research Inc (ESRI) for its .prj file format. EML provides a library of pre-defined coordinate systems that may be referred to by name in the horizCoordSysName element. A custom projection may be defined using this schema for any projection that does not appear in this dictionary.
5.2.8 The eml-storedProcedure module - Data tables resulting from procedures stored in a database
Links:
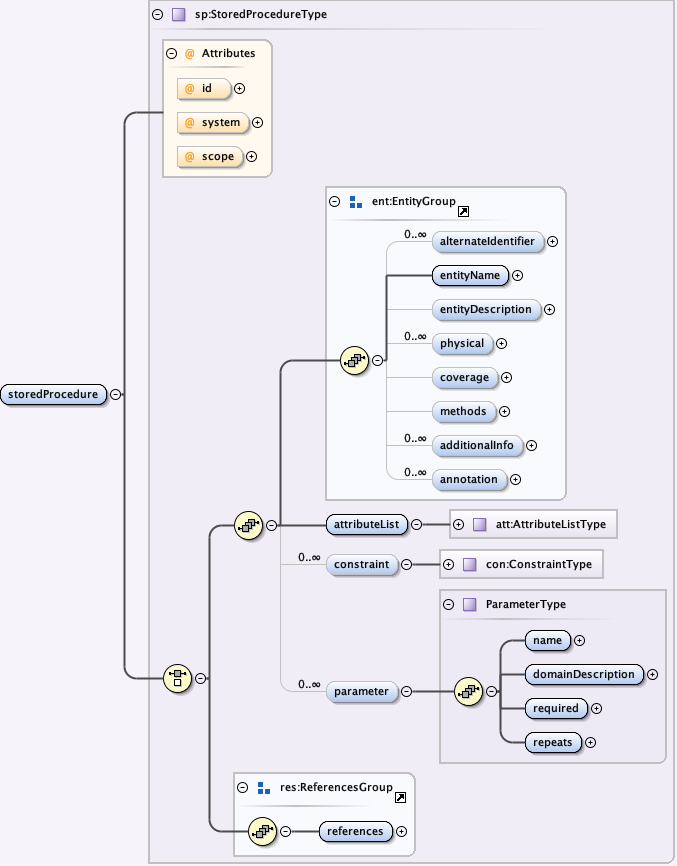{kind=link}
The storedProcedure module is meant to capture information on procedures that produce data output in the form of a data table. In an RDBMS one can code complex queries and transactions into stored procedures and then invoke them directly from front-end applications. It allows the optional description of any parameters that are expected to be passed to the procedure when it is called.
5.2.9 The eml-view module - Data tables resulting from a database query
Links:
{kind=link}
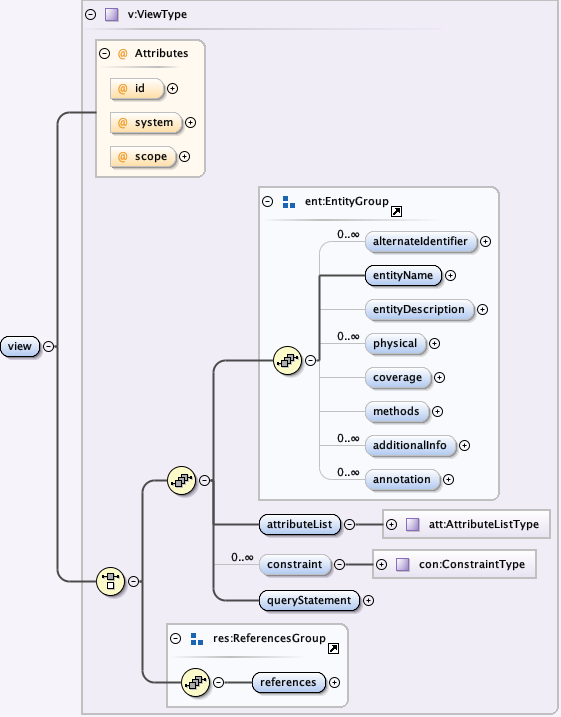
The eml-view module describes a view from a database management system. A view is a query statement that is stored as a database object and executed each time the view is called.
5.3 Discovery and Interpretation Modules
The following five modules are used to qualify the resources being described in more detail. They are used to describe the distribution of the metadata and data themselves, parties associated with the resource, the geographic, temporal, and taxonomic extents of the resource, the overall research context of the resource, and detailed methodology used for creating the resource. Some of these modules are imported directly into the top-level resource modules, often in many locations in order to limit the scope of the description. For instance, the eml-coverage module may be used for a particular column of a dataset, rather than the entire dataset as a whole.
5.3.1 The eml-physical module - Physical file format
Links:
{kind=link}
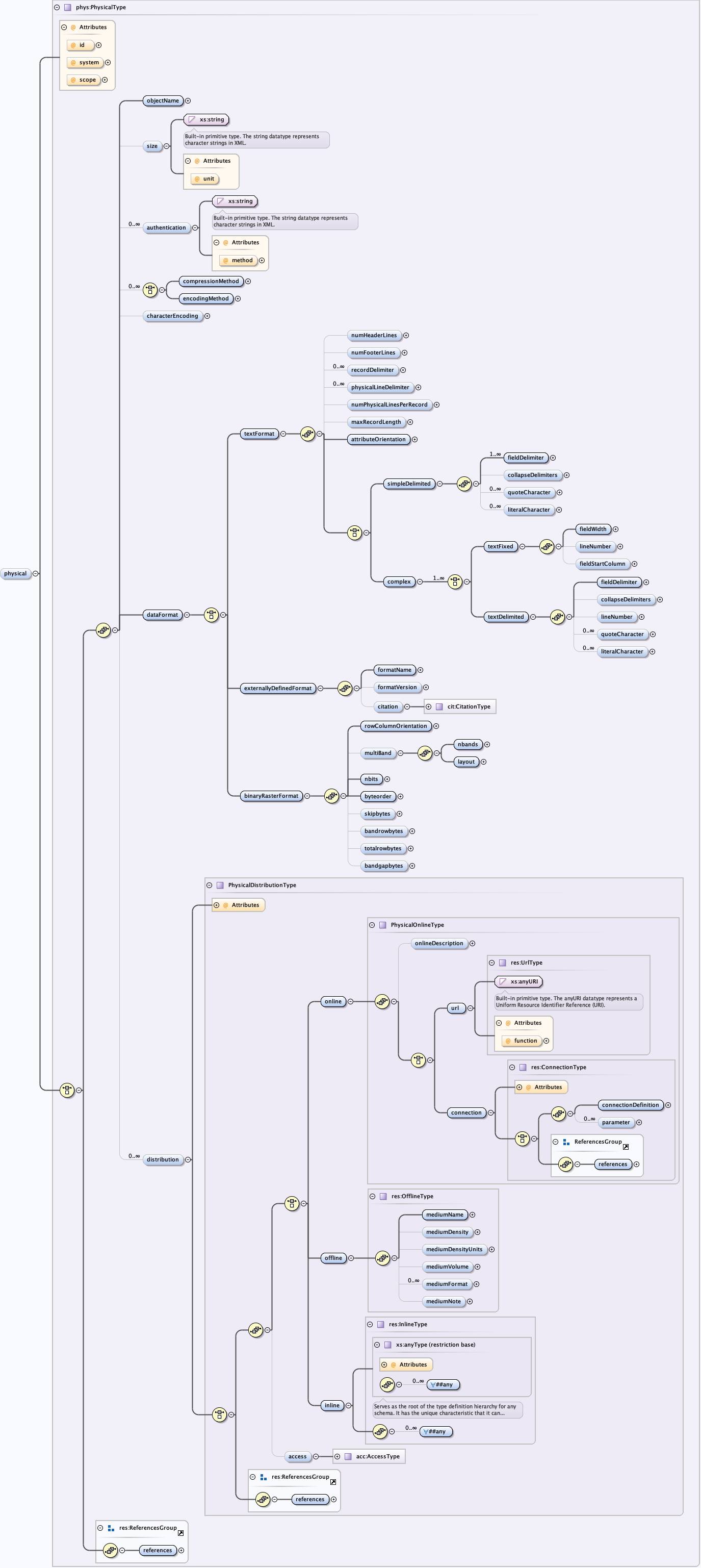
The eml-physical module describes the external and internal physical characteristics of a data object as well as the information required for its distribution. Examples of the external physical characteristics of a data object would be the filename, size, compression, encoding methods, and authentication of a file or byte stream. Internal physical characteristics describe the format of the data object being described. Both named binary or otherwise proprietary formats can be cited (e.g., Microsoft Access 2000), or text formats can be precisely described (e.g., ASCII text delimited with commas). For these text formats, it also includes the information needed to parse the data object to extract the entity and its attributes from the data object. Distribution information describes how to retrieve the data object. The retrieval information can be either online (e.g., a URL or other connection information) or offline (e.g., a data object residing on an archival tape).
The eml-physical module, like other modules, may be "referenced" via the <references> tag. This allows a physical document to be described once, and then used as a reference in other locations within the EML document via its ID.
5.3.2 The eml-party module - People and organization information
Links:
{kind=link}
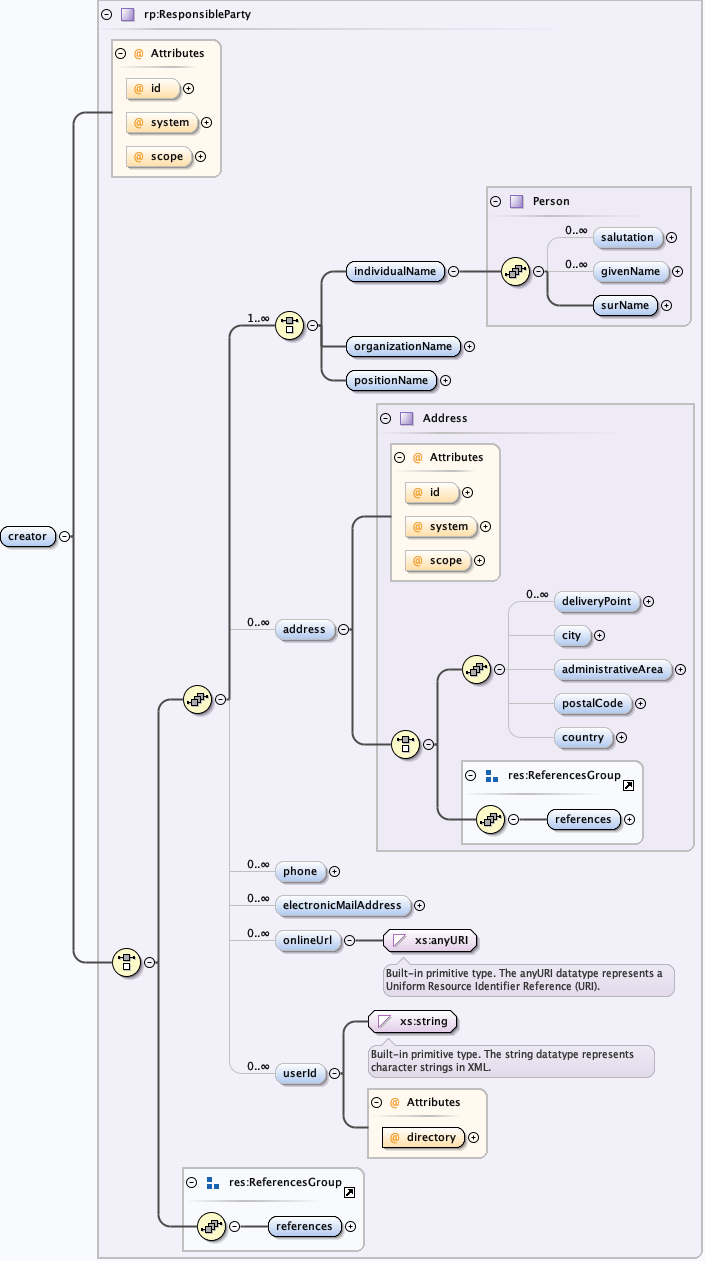
The eml-party module describes a responsible party and is typically used to name the creator of a resource or metadata document. A responsible party may be an individual person, an organization or a named position within an organization. The eml-party module contains detailed contact information. It is used throughout the other EML modules where detailed contact information is needed.
The eml-party module, like other modules, may be "referenced" via the <references> tag. This allows a party to be described once, and then used as a reference in other locations within the EML document via its ID.
5.3.3 The eml-coverage module - Geographic, temporal, and taxonomic extents of resources
Links:
{kind=link}
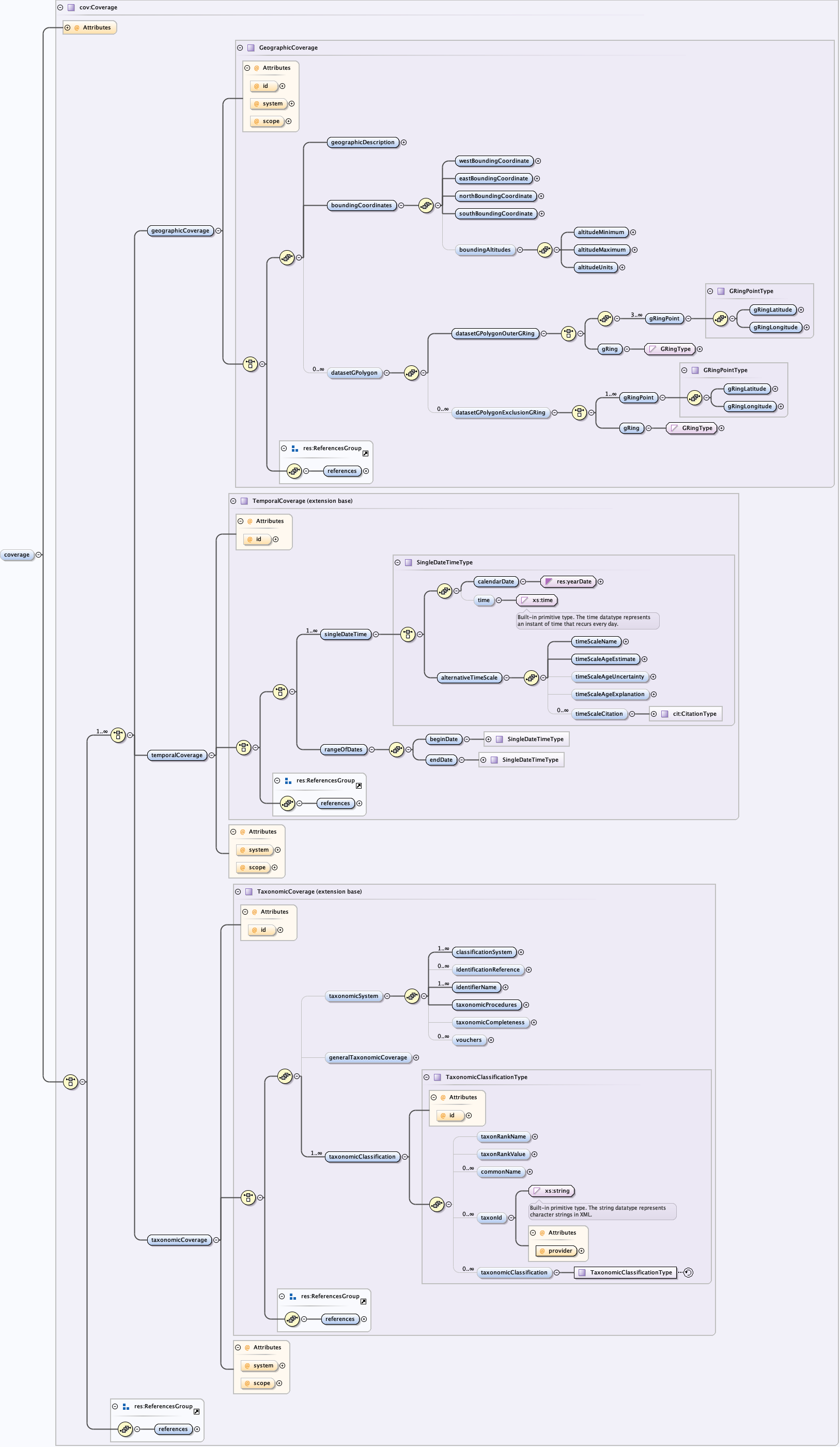
The eml-coverage module contains fields for describing the coverage of a resource in terms of time, space, and taxonomy. These coverages (temporal, spatial, and taxonomic) represent the extent of applicability of the resource in those domains. The Geographic coverage section allows for 2 means of expressing coverage on the surface of the earth: 1) via a set of bounding coordinates that define the North, South, East and West points in a rectangular area, optionally including a bounding altitude, and 2) using a G-Ring polygon definition, where an irregularly shaped area may be defined using a ordered list of latitude/longitude coordinates. A G-Ring may also include an "inner G-Ring" that defines one or more "cut-outs" in the area, i.e. the donut hole concept.
The temporal coverage section allows for the definition of either a single date or time, or a range of dates or times. These may be expressed as a calendar date according to the ISO 8601 Date and Time Specification, or by using an alternate time scale, such as the geologic time scale. Currently, EML does not have specific fields to indicate that a data resource may be "ongoing." Two examples are data tables that are planned to be appended in the future, or resources with complex connection definitions (such as to a database) which may return data in real time. It is important that EML be able to handle data from both the "producer" and "consumer" points of view, although currently the temporal coverage modules are designed for the latter. There is no universally acceptable recommendation for describing "ongoing" data within EML. Some groups have chosen to use the <alternateTimeScale> node for the end date, with a value of "ongoing," although this practice is not endorsed by the EML authors. A better solution could be to use very general content for the endDate (such as only the current year) so that the data are accurately described, and searches return datasets as expected. A future version of EML will accommodate such data types with coverage elements specific to their needs.
The taxonomic coverage section allows for detailed description of the taxonomic extent of the dataset or resource. The taxonomic classification consists of a recursive set of taxon rank names, their values, and their common names. This construct allows for a taxonomic hierarchy to be built to show the level of identification (e.g. Rank Name = Kingdom, Rank Value = Animalia, Common Name = Animals, and so on down the hierarchy.) The taxonomic coverage module also allows for the definition of the classification system in cases where alternative systems are used.
The eml-coverage module, like other modules, may be "referenced" via the <references> tag. This allows the coverage extent to be described once, and then used as a reference in other locations within the EML document via its ID.
5.3.4 The eml-project module - Research context information for resources
Links:
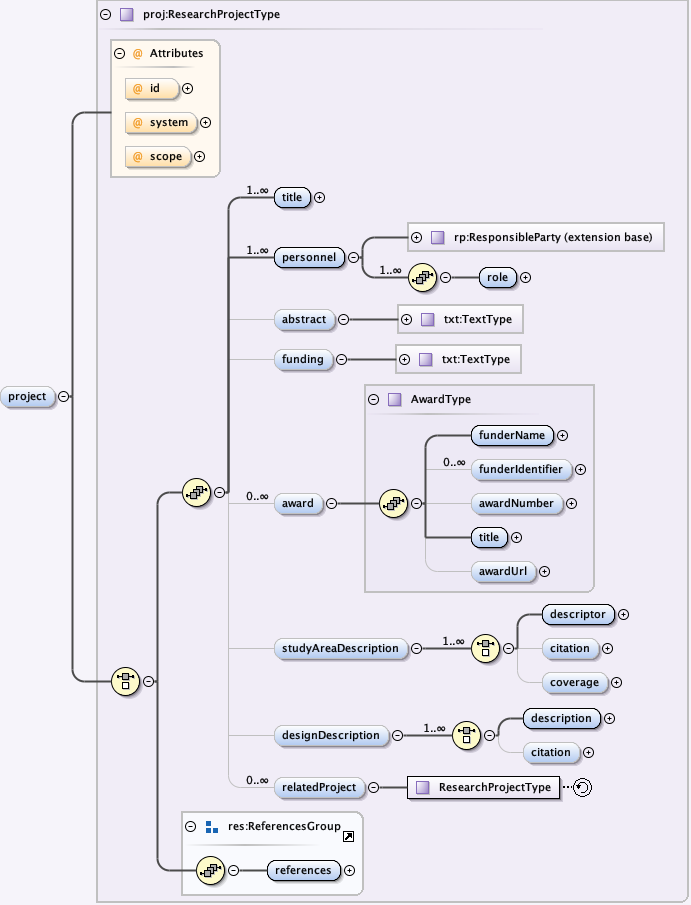{kind=link}
The eml-project module describes the research context in which the dataset was created, including descriptions of over-all motivations and goals, funding, personnel, description of the study area etc. This is also the module to describe the design of the project: the scientific questions being asked, the architecture of the design, etc. This module is used to place the dataset that is being documented into its larger research context.
The eml-project module, like other modules, may be "referenced" via the <references> tag. This allows a research project to be described once, and then used as a reference in other locations within the EML document via its ID.
5.3.5 The eml-methods module - Methodological information for resources
Links:
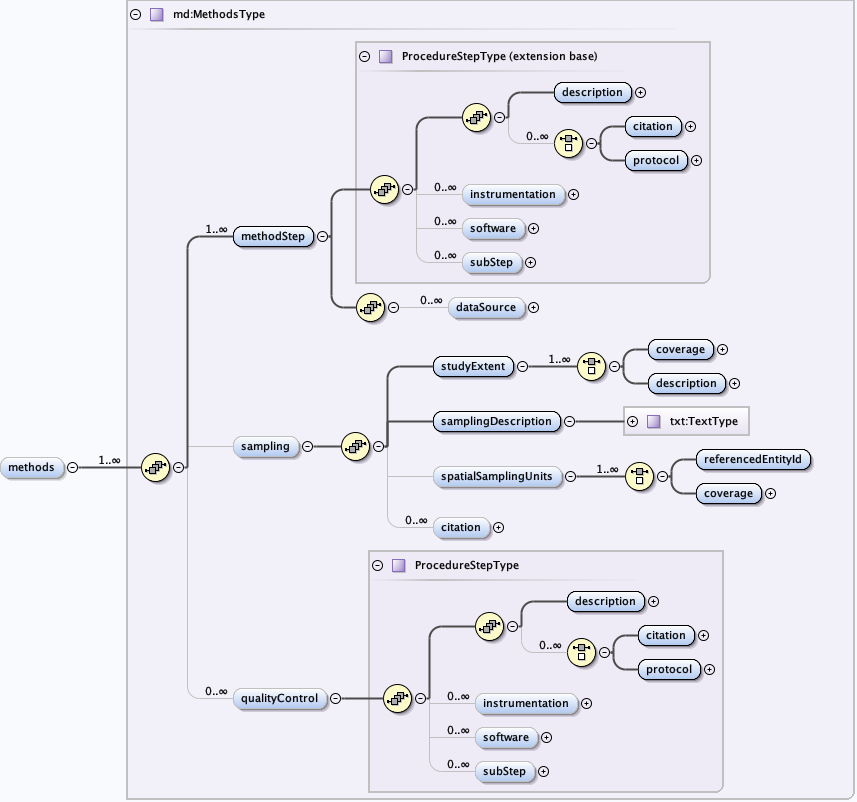{kind=link}
The eml-methods module describes the methods followed in the creation of the dataset, including description of field, laboratory and processing steps, sampling methods and units, quality control procedures. The eml-methods module is used to describe the actual procedures that are used in the creation or the subsequent processing of a dataset. Likewise, eml-methods is used to describe processes that have been used to define / improve the quality of a data file, or to identify potential problems with the data file. Note that the eml-protocol module is intended to be used to document a prescribed procedure, whereas the eml-method module is used to describe procedures that were actually performed. The distinction is that the use of the term "protocol" is used in the "prescriptive" sense, and the term "method" is used in the "descriptive" sense. This distinction allows managers to build a protocol library of well-known, established protocols (procedures), but also document what procedure was truly performed in relation to the established protocol. The method may have diverged from the protocol purposefully, or perhaps incidentally, but the procedural lineage is still preserved and understandable.
5.4 Utility Modules
The following modules are used to highlight the information being documented in each of the above modules where prose may be needed to convey the critical metadata. The eml-text module provides a number of text-based constructs to enhance a document (including sections, paragraphs, lists, subscript, superscript, emphasis, etc.)
5.4.1 The eml-text module - Text field formatting
Links:
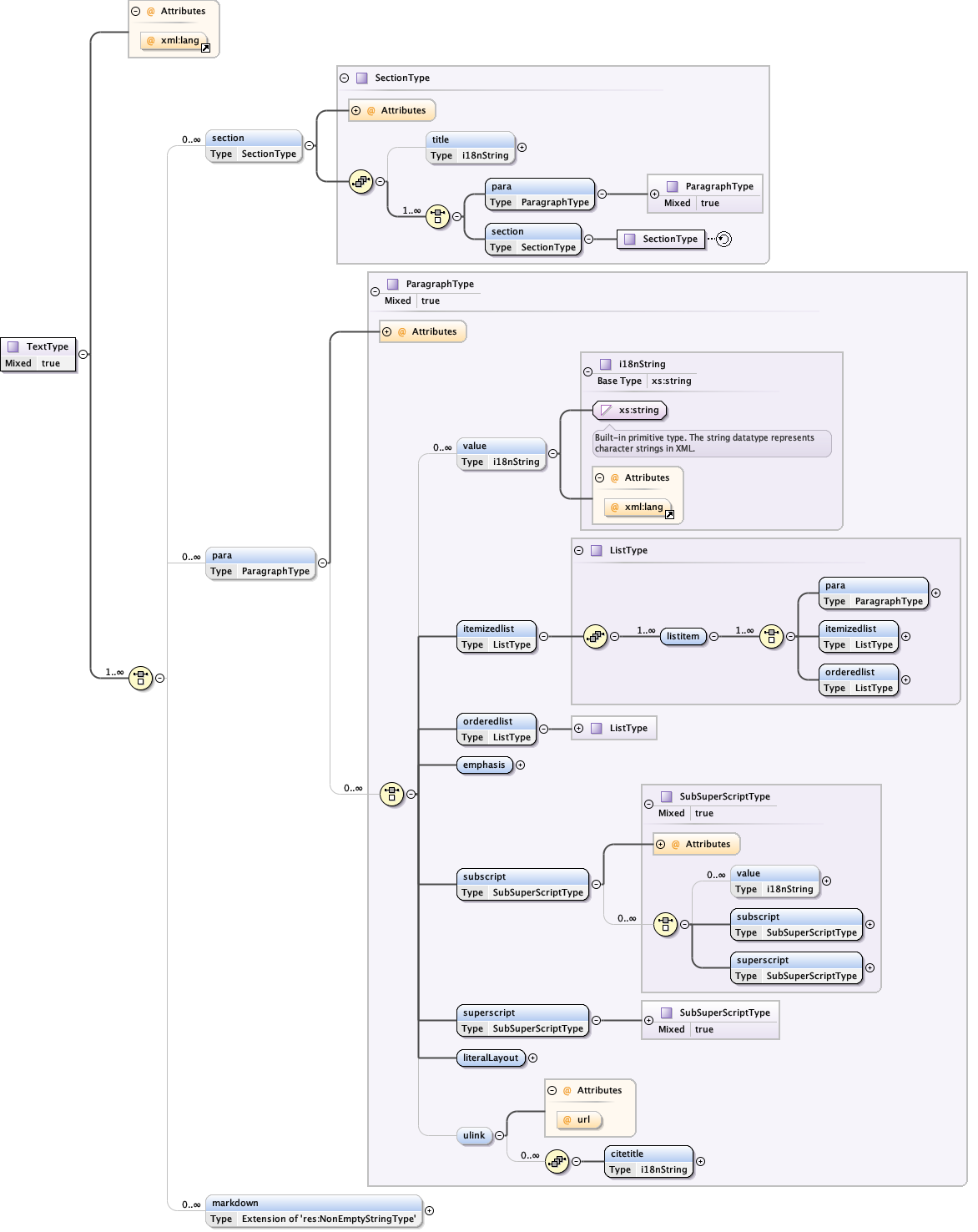{kind=link}
The eml-text module is a wrapper container that allows general text descriptions to be used within the various modules of eml. It can include either structured or unstructured text blocks. It isn’t really appropriate to use this module outside of the context of a parent module, because the parent module determines the appropriate context to which this text description applies. The eml-text module allows one to provide structure to a text description in order to convey concepts such as sections (paragraphs), hierarchy (ordered and unordered lists), emphasis (bold, superscript, subscript), etc. The structured elements can be specified using a subset of DocBook so the predefined DocBook stylesheets can be used to style EML fields that implement this module, or alternatively can be specified using Markdown text blocks. Combinations of plain text, docbook sections, and markdown sections can be interleaved in any order, but most people will likely find the markdown syntax the easiest to use.
Markdown sections, which are new to EML 2.2.0, provide significant new flexibility
in how to format text for human readability. The following example introduction
element that exercises a number of the markdown features.
<introduction>
<markdown>
An introduction goes here, with *italics* and **bold** text, and other markdown niceties.
It can include multiple paragraphs. And these paragraphs should have enough text to wrap in a wide browser. So, repeat that last thought. And these paragraphs should have enough text to wrap in a wide browser. So, repeat that last thought.
Text can also cite other works, such as [@jones_2001], in which case the associated key must be present
as either the citation identifier in a `bibtex` element in the EML document, or as the `id` attribute on
one of the `citation` elements in the EML document. These identifiers must be unique across the document. Tools
such as Pandoc will readily convert these citations and citation entries into various formats, including HTML, PDF,
and others.
And bulleted lists are also supported:
- Science
- Engineering
- Math
It can also include equations:
$$\left( x + a \right)^{n} = \sum_{k = 0}^{n}{\left( \frac{n}{k} \right)x^{k}a^{n - k}}$$
Plus, it can include all of the other features of [Github Flavored Markdown (GFM)](https://github.github.com/gfm/).
</markdown>
</introduction>Because Markdown treats whitespace as significant in formatting, it is important to consistently embed Markdown text inside of an EML document. For example, bulleted lists and other structures within Markdown are dependent on indenting the raw markdown text. Thus, authors and processors should pay close attention to formatting within the markdown block. In particular, if the XML document within which the markdown block is embedded is in an indented hierarchy using whitespace, then the first non-whitespace character of the markdown block defines the column for the leftmost column of the markdown, and all subsequent markdown should be indented relative to that column. For example, if the first character of the markdown is in column 16 of the document, then all subsequent markdown lines in that block should also start on column 16. A bulleted list would start on column 16, and its sublist would be indented four space to column 20.
In the above example, the first line of the markdown block is indented by 8
spaces, and so that becomes the default indenting level for the markdown block.
EML processors should first extract the markdown text from the XML document
without normalizing any whitespace, then remove the default leading whitespace
(in this case, 8 space characters), and then pass the resulting text to a
conforming markdown parser that handles Github Flavored Markdown (GFM). The
resulting parse tree can then be used for display in applications.
Further details about handling and authoring markdown are included in the
definition of the markdown element in the eml-text module.
5.4.2 The eml-semantics module - Semantic annotations for formalized statements about EML components
Links:
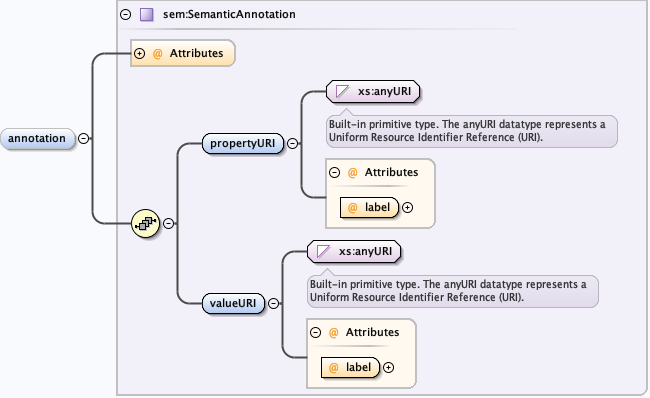{kind=link}
The eml-semantics module defines types and elements for annotating other structures within EML with semantically-precise statements from various controlled vocabularies. This is accomplished by associating the global URI for a property and value with elements from EML, such as an attribute, an entity, or a dataset. It is used throughout the other EML modules where detailed semantic information is needed. For example, given an EML attribute named “tmpair”, one might want to indicate semantically that the attribute is measuring the property “Temperature” from a sample of the entity “Air”, where both of those terms are defined precisely in controlled vocabularies. The eml-semantics module defines an ‘annotation’ element and associated type that can be used within EML resources (dataset, software, etc.), EML Entities (dataTable, spatialRaster, spatialVector, otherEntity), and EML Attributes. They can also be applied within the EML additionalMetadata field to label arbitrary structures within EML, in which case the subject of the annotation is the element listed in the describes element within the additionalMetadata field.
5.4.3 The eml-access module - Access control rules for resources
DEPRECATED
- While eml-access has been part of the standard for many years, use has been
extremely limited, and most systems seem to omit and ignore the
accesselements in the document in favor of using repository-specific mechanisms to control access. Therefore, EML 2.2.0 deprecates use of theaccesselements in the main body of EML documents, with the exception of use within theadditionalMetadataelement. As this is a backwards incompatible change, the elements are still available in EML 2.2.0, but users should expect schema changes to occur in a future release that eliminate the use ofaccesselements outside ofadditionalMetadata. In addition, because authorization systems are system-dependent, the content within anyaccesselement should be considered advisory and may not reflect the actual authorization policies in place at a given point in time in a given repository.
Links:
{kind=link}
The eml-access module describes the level of access that is to be allowed or denied to a resource for a particular user or group of users, and can be described independently for metadata and data. The eml-access module uses a reference to a particular authentication system to determine the set of principals (users or groups) that can be specified in the access rules. The special principal 'public' can be used to indicate that any user or group has access permission, thereby making it easier to specify that anonymous access is allowed.
There are two mechanisms for including access control via the eml-access module:
The top-level "eml" element may have an optional <access> element that is used to establish the default access control for the entire EML package. If this access element is omitted from the document, then the package submitter should be given full access to the package but all other users should be denied all access. To allow the package to be publicly viewable, the EML author must explicitly include a rule stating so. Barring the existence of a distribution-level <access> element (see below), access to data entities will be controlled by the package-level <access> element in the <eml> element.
Exceptions for particular entity-level components of the package can be controlled at a finer grain by using an access description in that entity's physical/distribution tree. When access control rules are specified at this level, they apply only to the data in the parent distribution element, and not to the metadata. Thus, it will control access to the content of the <inline> element, as well as resources that are referenced by the <online/url> and <online/connection> paths. These exceptions to access for particular data resources are applied after the default access rules at the package-level have been applied, so they effectively override the default rules when they overlap.
In previous versions of EML access rules for entity-level distribution were contained in <additionalMetadata> sections and referenced via the <describes> tag. Although in theory these could have referenced any node, in application such node-level access control is problematic. Since the most common uses of access control rules were to limit access to specific data entities, the access tree has been placed there explicitly in EML 2.1.0.
Access is specified with a choice of child elements, either <allow> or <deny>. Within these rules, values can be assigned for each <principal> using the <permission> element. Users given "read" permission can view the resource; "write" allows changes to the resource excluding changes to the access rules; "changePermission" includes "write" plus the changing of access rules. Users allowed "all" permissions; may do all of the above. Access to data and metadata is affected by the order attribute of the <access> element. It is possible for a deny rule to override an allow rule, and vice versa. In the case where the order attribute is set to "allowFirst", and there are rules similar to the following (with non-critical sections deleted):
<deny>
<principal>public</principal>
<permission>read</permission>
</deny>
<allow>
<principal>uid=alice,o=NASA,dc=ecoinformatics,dc=org</principal>
<permission>read</permission>
</allow>the principal "uid=alice ..." will be denied access, because it is a member of the special "public" principal, and the deny rule is processed second. For this allow rule to truly allow access to that principal, the order attribute should be set to "denyFirst", and the allow rule will override the deny rule when it is processed second.
An example is given below, with non-critical sections deleted:
<eml>
<access
authSystem="ldap://ldap.ecoinformatics.org:389/dc=ecoinformatics,dc=org"
order="allowFirst">
<allow>
<principal>uid=alice,o=NASA,dc=ecoinformatics,dc=org</principal>
<permission>read</permission>
<permission>write</permission>
<allow>
</access>
<dataset>
...
...
<dataTable id="entity123">
...
<physical>
...
<distribution>
...
<access id="access123"
authSystem="ldap://ldap.ecoinformatics.org:389/dc=ecoinformatics,dc=org"
order="allowFirst">
<deny>
<principal>uid=alice,o=NASA,dc=ecoinformatics,dc=org</principal>
<permission>write</permission>
</deny>
</access>
</distribution>
</physical>
</dataTable>
<dataTable id="entity234">
...
<physical>
...
<distribution>
...
<access>
<references>access123</references>
</access>
</distribution>
</physical>
</dataTable>
...
</dataset>
<eml>In this example, the overall default access is to allow the user=alice (but no one else) to read and write all metadata and data. However, under "entity123" and "entity234", there is an additional rule saying that user=alice does not have write permission. The net effect is that Alice can read and make changes to the metadata, but cannot make changes to the two data entities. In addition, Alice cannot change these access rules; although the submitter can.
This example also shows how the eml-access module, like other modules, may be "referenced" via the <references> tag. This allows an access control document to be described once, and then used as a reference in other locations within the EML document via its ID.
In summary, access rules can be applied in two places in an eml document. Default access rules are established in the top <access> element for the main eml document (e.g., "/eml/access"). These default rules can be overridden for particular data entities by adding additional <access> elements in the physical/distribution trees of those entities.